阿里云EMR最佳實踐與容災(zāi) 構(gòu)建高可靠的數(shù)據(jù)處理與存儲服務(wù)體系
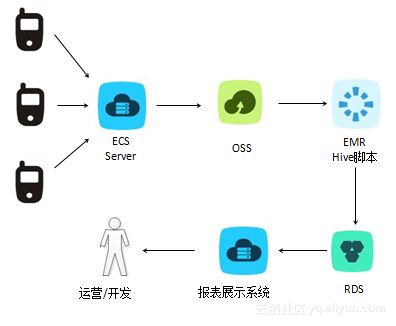
阿里云E-MapReduce(EMR)作為一款全托管的云原生大數(shù)據(jù)平臺,為企業(yè)提供了高效、彈性的數(shù)據(jù)處理和存儲解決方案。結(jié)合最佳實踐與完善的容災(zāi)策略,可以構(gòu)建出高可靠、高性能、可擴展的大數(shù)據(jù)服務(wù)架構(gòu),確保業(yè)務(wù)連續(xù)性與數(shù)據(jù)安全。
一、數(shù)據(jù)處理與存儲服務(wù)最佳實踐
1. 集群規(guī)劃與資源配置
- 按需選擇節(jié)點類型:根據(jù)計算密集型(如Spark、Flink)或存儲密集型(如HDFS)工作負載,選擇ECS實例類型(如計算型、大數(shù)據(jù)型)。計算任務(wù)使用計算優(yōu)化型實例,數(shù)據(jù)存儲使用本地SSD或高效云盤的大數(shù)據(jù)型實例,以優(yōu)化性價比。
- 彈性伸縮策略:利用EMR的彈性伸縮功能,基于集群負載(如YARN資源隊列使用率、CPU/內(nèi)存指標)自動增加或減少Task節(jié)點,在業(yè)務(wù)高峰時擴容以保證性能,低峰時縮容以節(jié)約成本。
- 存儲與計算分離:推薦將數(shù)據(jù)持久化存儲在OSS(對象存儲)中,而非僅依賴HDFS。OSS提供高持久性、無限擴展和低成本存儲,EMR集群可掛載OSS作為數(shù)據(jù)湖,實現(xiàn)計算集群的輕量化與靈活啟停。
2. 數(shù)據(jù)開發(fā)與處理優(yōu)化
- 作業(yè)調(diào)度與依賴管理:使用阿里云DataWorks或EMR Workflow進行作業(yè)編排,實現(xiàn)復(fù)雜DAG任務(wù)調(diào)度,并設(shè)置任務(wù)間依賴與失敗重試機制,提升數(shù)據(jù)處理流水線的可靠性。
- 計算引擎調(diào)優(yōu):針對Spark、Hive等引擎,根據(jù)數(shù)據(jù)量調(diào)整Executor數(shù)量、內(nèi)存分配與并行度;啟用動態(tài)資源分配(DRA)以提高資源利用率;對于實時處理,使用Flink并合理設(shè)置Checkpoint間隔與狀態(tài)后端(如RocksDB)。
- 數(shù)據(jù)格式與壓縮:采用列式存儲格式(如Parquet、ORC)并配合Snappy或Zstd壓縮,減少I/O與存儲開銷,提升查詢性能。
3. 數(shù)據(jù)管理與安全
- 權(quán)限與訪問控制:通過Ranger或RAM(資源訪問管理)實現(xiàn)細粒度的數(shù)據(jù)權(quán)限管控,對Hive表、HDFS路徑、OSS Bucket設(shè)置用戶/角色訪問策略,并集成Kerberos進行身份認證。
- 數(shù)據(jù)生命周期管理:結(jié)合OSS生命周期規(guī)則,將冷數(shù)據(jù)自動轉(zhuǎn)換為低頻或歸檔存儲,降低存儲成本;使用EMR Metastore或DLF(數(shù)據(jù)湖構(gòu)建)統(tǒng)一管理元數(shù)據(jù),確保數(shù)據(jù)一致性。
- 監(jiān)控與運維:利用云監(jiān)控、EMR控制臺和Prometheus監(jiān)控集群健康度、作業(yè)運行狀態(tài)與資源使用情況,設(shè)置告警閾值(如節(jié)點故障、磁盤使用率>80%),并通過日志服務(wù)(SLS)集中收集與分析日志。
二、容災(zāi)架構(gòu)設(shè)計與實施
1. 跨可用區(qū)(AZ)高可用部署
- 核心組件高可用:在創(chuàng)建EMR集群時,選擇多可用區(qū)部署模式,確保Master節(jié)點(如HDFS NameNode、YARN ResourceManager)跨AZ分布,避免單點故障。啟用HDFS HA、YARN HA及ZooKeeper集群,保障服務(wù)連續(xù)性。
- 數(shù)據(jù)冗余存儲:將原始數(shù)據(jù)與處理結(jié)果同時存儲于OSS,利用OSS的同城冗余存儲(LRS)或跨區(qū)域冗余存儲(ZRS/CRR)功能,實現(xiàn)數(shù)據(jù)跨機房或跨地域復(fù)制,滿足不同級別的容災(zāi)需求。
2. 業(yè)務(wù)級容災(zāi)與備份恢復(fù)
- 集群級容災(zāi):在多個地域(如華東1、華北2)部署獨立的EMR集群,通過Data Integration或DataWorks數(shù)據(jù)同步任務(wù),將關(guān)鍵數(shù)據(jù)實時或定期同步至災(zāi)備集群。當主集群發(fā)生地域級故障時,可快速切換至災(zāi)備集群接管數(shù)據(jù)處理任務(wù)。
- 元數(shù)據(jù)與配置備份:定期備份Hive Metastore、Ranger策略等元數(shù)據(jù)至OSS或NAS,并利用EMR的集群模板功能保存集群配置,以便在災(zāi)難發(fā)生時快速重建集群。
- 恢復(fù)時間目標(RTO)與恢復(fù)點目標(RPO)定義:根據(jù)業(yè)務(wù)重要性制定容災(zāi)預(yù)案,明確RTO(如小時級)和RPO(如分鐘級數(shù)據(jù)丟失)。通過定期容災(zāi)演練(如切換測試),驗證恢復(fù)流程的有效性。
3. 混合云與多云容災(zāi)擴展
- 對于混合云場景,可通過阿里云高速通道或VPN網(wǎng)關(guān),將本地數(shù)據(jù)中心與阿里云EMR連通,實現(xiàn)數(shù)據(jù)雙向同步與災(zāi)備。利用阿里云DTS(數(shù)據(jù)傳輸服務(wù))或開源工具(如Sqoop、DistCp)進行數(shù)據(jù)遷移。
- 考慮多云架構(gòu)時,可將OSS數(shù)據(jù)鏡像至其他云存儲服務(wù)(如AWS S3),并在其他云平臺部署備用EMR集群(或類似服務(wù)),通過腳本自動化實現(xiàn)跨云容災(zāi),但需注意網(wǎng)絡(luò)延遲與成本管理。
三、
阿里云EMR結(jié)合OSS等存儲服務(wù),為企業(yè)提供了從數(shù)據(jù)處理到存儲的全鏈路解決方案。通過遵循最佳實踐優(yōu)化性能與成本,并設(shè)計跨AZ、跨地域乃至跨云的容災(zāi)架構(gòu),可顯著提升大數(shù)據(jù)服務(wù)的可靠性。建議企業(yè)根據(jù)自身業(yè)務(wù)需求(如數(shù)據(jù)規(guī)模、實時性要求、合規(guī)性)靈活選擇策略,并持續(xù)監(jiān)控與迭代,以構(gòu)建適應(yīng)未來發(fā)展的數(shù)據(jù)基礎(chǔ)設(shè)施。
如若轉(zhuǎn)載,請注明出處:http://www.ncf6j.cn/product/49.html
更新時間:2026-01-06 07:00:49